Цифровое «книгопечатание» [Сергей Бесараб stean] (fb2) читать онлайн
- Цифровое «книгопечатание» 496 Кб, 36с. скачать: (fb2) читать: (полностью) - (постранично) - Сергей Бесараб (stean)
[Настройки текста] [Cбросить фильтры]
[Оглавление]
Сергей Бесараб aka stean ЦИФРОВОЕ «КНИГОПЕЧАТАНИЕ»
Пошаговое руководство по оцифровке книг
Часть 1
Задеть больную тему качественного перевода бумажных изданий в цифровую форму заставляет сама жизнь. В электронных интернет-библиотеках книги появляются довольно новые, но вот качество их обработки оставляет желать лучшего. Страницы не обрезаны, картинки размыты, текстовый (OCR) слой не добавлен и ещё много всяких больших и маленьких огрехов.Понимаю, бывают случаи, когда необходимо быстро создать электронную копию для собственных нужд, но должно быть совестно выкладывать такой полуфабрикат в Сеть и заставлять людей страдать (ибо чтением назвать процесс просмотра таких «шедевров» язык не поворачивается). Если уж у вас нет сил, чтобы отсканированный «манускрипт» привести в приемлемый вид, — просто заархивируйте сканы и выложите на специализированных форумах. Поверьте, всегда найдутся люди, готовые пожертвовать своим временем для создания электронного варианта книги, за который потом не было бы стыдно перед её читателями. Итак, возвращаясь к нашим баранам. Основы «DJVU-печатания» были рассмотрены в «Компьютерных вестях» №№ 5–6 за 2007 год Андреем Ачиновичем. Дабы не переписывать уже имеющуюся информацию, остановимся на некоторых нюансах, связанных, в основном, с качеством создаваемых сканов книг, а также на появившихся нововведениях и улучшениях, с позволения сказать, техпроцесса. Времени после публикации вышеупомянутой статьи прошло довольно много — появились новые версии прежних программ, да и разработаны новые утилиты. Конечно, тема процесса создания книг затёрта уже практически до дыр на различных форумах и в печатных изданиях, но, как ни странно, улучшению качества недавно отсканированных книг это не способствует. Цель статьи — поднять уровень уже существующих «Гуттенбергов» века компьютерного и привлечь новичков к этому важному делу.
Этап первый: сканирование
Здесь особенных премудростей нет — как правило, выставления разрешения 300 dpi для страницы в формате Gray вполне достаточно. Всё остальное зависит только от сканера. Кстати, обложку книги и особо важные иллюстрации я всё-таки рекомендую сканировать в цвете (16- или 24-битном), опять же — для того, чтобы наша цифровая книжка получилась красивая. Кроме того, желательно разворот книги на сканерном стекле особенно не перекашивать и не менять каждый раз его местоположение. Потом будет проще всё лишнее обрезать (не стоит полностью уповать на возможности автоматического разворота и разрезания страниц, имеющихся в пакетах типа ABBYY FineReader). Сканировать в разрешении больше 300 dpi смысла нет, так как, во-первых, увеличивается износ механики сканера (к примеру, мой старый Mustek 12000 SP+ на 300 dpi сканирует страницу за один проход, а на 600 останавливается четыре раза), а во-вторых, разрешение впоследствии можно исправить вручную, с помощью специализированного ПО (об этом ниже). Сканирование, на мой взгляд, во всей технологии e-book самый нудный процесс, и тенденции к облегчению и упрощению пока не намечается. Всё равно переворачивать страницы приходится вручную. Хотя, к примеру, в некоторых сканерах производства HP возможности пакетного сканирования сводят неудобства до минимума. Настроил один раз качество и разрешение сканируемой картинки — и знай себе переворачивай страницы да не забывай нажимать кнопку «Scan» на крышке сканера. Всё остальное уже сделает автоматика. В результате в выбранную папку будут ложиться готовые сканы. Что же касается владельцев не столь продвинутой техники, то им придётся пользоваться старым добрым IrfanView с установленным специализированным плагином AutoScan (labun.com/autoscan.zip) от Eugen Labun. Скачиваем данный архив со страницы автора и распаковываем файлы autoscan.vbs и AutoWindowEnabler.exe в директорию с установленным IrfanView. Далее заходим в меню Файл > Получить/Отсканировать, выбираем режим сканирования «Одно изображение» и сканируем и сохраняем образец с нужными нам параметрами. Назвать первый скан лучше всего 001.* (так советует автор). Теперь запускаем распакованный ранее файл autoscan.vbs. Программа покажет заданные ранее параметры и после нажатия на «OK» начнётся автоматическое сканирование через определённые промежутки. Файлы сохраняются с именами 001.*, 002.*, 003.* и т. д. в ту же директорию, где и первый файл. Файл AutoWindowEnabler.exe предназначен для слежения за окном IrfanView (часто бывает, что во время открытого TWAIN-диалога окно просмотрщика становится неактивным, а то и вовсе исчезает с экрана). Кстати, если вдруг скрипт что-то воспроизводит не так, как бы вам хотелось, или просто нужно изменить настройки — достаточно просто ещё раз произвести тестовый запуск IrfanView, а потом опять запустить макрос. Или же, щелкнув правой кнопкой мыши по файлу autoscan.vbs, выбрать «Изменить» и внести необходимые параметры вручную:' You can change these settings:
StartingIndex = 1
Increment = 1
NumberOfDigits = 3
SkipExistingFiles = True ' True or False
DelayBetweenScans = 0 ' Seconds
SetScanDPI = False ' Try to set to True only if
' Your scanner does not preserve scan resolution
DPI = 300 ' has no effect if SetScanDPI is False
Как можно догадаться, StartingIndex показывает порядковый номер первого файла (от которого будет вестись счёт), Increment — величину, на которую будет увеличиваться порядковый номер каждой новой сканируемой страницы. NumberOfDigits — число знаков в цифровом индексе файла. DelayBetweenScans — задержку между окончанием одного прохода сканера и началом следующего (выставляется она строго экспериментальным методом и занимает ровно столько времени, сколько вам потребуется, чтобы перевернуть страницу). SetScanDPI — принудительное задание разрешения сканирования (необходимо в случае, если TWAIN-драйвер сканера такой возможности не предоставляет). Может принимать значение либо TRUE, либо FALSE; по умолчанию стоит второе. DPI — значение разрешения сканирования в случае выбора предыдущего параметра «TRUE». Сохраняем исправленный документ (отмечу, что лезть ручками можно только (!) в данную секцию, упаси вас бог экспериментировать с остальными, недоступными разуму рядового пользователя, параметрами — в результате таких необдуманных действий вместо картинки можно получить чёрти что).
Более продвинутым является использование специальной утилиты для потокового сканирования PaperCapture (djvu-soft.narod.ru/recogniform_paper_capture.rar) от компании Recogniform. После скачивания архива и его распаковки первым делом стоит запустить имеющийся. reg файл, дабы в дальнейшем избежать неожиданных действий со стороны программы. Затем просто запускаем PaperCapture.exe. В меню File > Scanner Settings создаём новый профиль с любым названием и активируем радио-кнопку рядом со строкой «This Scanner», где в выпадающем меню выбираем установленные на ПК устройства (если их у вас, конечно, несколько). Окно «Parameter» позволяет настроить параметры, с которыми будет сканироваться каждая новая страница. Я выставил минимальное количество наиболее необходимых:
Auto Rotate=Yes;
Auto Deskew=Yes;
чтобы получаемая картинка сначала разворачивалась (для двухстраничного скана), а потом выравнивалась (всё остальное можно качественно оформить на этапе «ретуширования» чернового материала). Жмём ОК и Ctrl+A. Остаётся только наблюдать за процессом сканирования и контролировать качество по отображаемым в окне программы эскизам. Кстати, результат пакетного сканирования можно сохранить не только в графический формат, но сразу и в PDF-файл (это на случай сканирования, к примеру, конспекта лекций).
Для любителей «глубокого копания» могу посоветовать использование пакета FastScan, который вместе с инструкцией по использованию можно скачать с «рапидшары» (rs101cg2.rapidshare.com/files/ 36486343/11054328/FastScan.rar). За основу там берется уже нам знакомый IrfanView, утилита-автоматизатор AutoRecorder 3.3 и программа для точного определения положения курсора Pixie 3.1. Первоначальная настройка ведется с помощью встроенной в Windows утилиты WIA (предназначенной специально для работы с цифровыми фотоаппаратами и сканерами). Доступна работа с ней после установки драйверов на оборудование, в которых имеется поддержка вышеупомянутой программы. Так как у меня в наличии таких драйверов не было, особенно акцентировать внимание на настройке этого комплекса программ и создании скрипта для сканирования я не стал. Скачав вышеупомянутый архив, внутри можно найти очень подробное иллюстрированное руководство по работе с комплексом программ. Так что если предложенные мною способы вас чем-то не устроят — всегда есть возможность пошевелить мозгами и попробовать данный способ (опять же, при условии, что в наличии у вас имеется подходящая модель сканера, а это практически все современные модели).
Применять для сканирования ABBYY FineReader всех версий до 9-й я не советую, ввиду того, что зачастую текст необратимо перекашивается. В 9-й же желательно в меню Options убрать галочку рядом со строкой «Исправлять перекос страниц». Что касается формата, в котором будет сохраняться черновой материал, то лучше всего использовать TIFF, потому что широко популярный JPEG размывает картинки, что в случае копии книги, по-моему, совершенно неприемлемо. Формат TIFF в случае сканов оттенков серого и цветных даёт лучшие результаты со сжатием по механизму LZW (без потери качества), для битовых чёрно-белых лучше всего применять сжатие по механизму CCIT FAX G4 (если вы сразу сканируете материал такой «битности»). Принципиальная их разница для рядового пользователя только в том, что каждый используется для своей определённой глубины цвета.
Итак, все основные нюансы мы обсудили. Сканируем выбранную книгу, а после окончания переходим ко второму этапу: ретушь и облагораживание. Впрочем, об этом уже в следующей части статьи.
Часть 2
Этап второй: ретушь и «облагораживание»
Наверное, это самый важный этап предварительной обработки картинок, от которого напрямую зависит качество будущей книги. Первым делом стоит упорядочить освещённость страниц и устранить маленькие недочёты (перекос страниц, мелкий мусор и появившиеся от разворота книги тени), а также привести страницы к чёрно-белому, бинарному, состоянию с наименьшими потерями в качестве. Нам понадобятся следующие инструменты: программа ScanKromsator v5.6 Full от Bolega (djvu-soft0001.nxt.ru/scan_kromsator_v5_6a_full.rar) и Book Restorer v4.1 (doronin.nnov.ru/djvu/BR41en.rar). Имеются, конечно, и другие разработки схожей функциональности (вроде ImageProcessor 4.5 (djvu-3soft.narod.ru/recogniform_image_processor_4_5_bin.rar) или CPC Tool v5.21 (djvu-4soft.narod.ru/cpc_tool_5_21.rar), но они имеют слабую функциональность, да ещё и глючат. Сначала нужно развернуть все странички на 90° (делать это умеют даже самые простые программы, я рекомендую IrfanView в режиме «Пакетное преобразование»). Для устранения световых дефектов вполне сгодится программа Book Restorer. В меню Book > New задаём название проекта книги и её месторасположение. Далее в меню Insert выбираем пункт Import files и добавляем нужные нам картинки (я делаю так — выбираю последнюю по порядковому номеру картинку, зажимаю Shift и щёлкаю по первой картинке в списке), которые сразу начинают отображаться в виде эскизов. Одновременно активным становится диалоговое меню Restoration, которое нам и нужно. Итак, щёлкаем по первой в списке странице и в меню инструментов Restoration выбираем пункт Lighting correction (двойным щелчком). Перед нами открывается диалоговое окно с двумя закладками: Lighting correction 1D и Lighting correction 2D. Опытным путём установлено, что лучший результат даёт закладка коррекции по двум измерениям, значит, так и будем делать. Проверяем наличие галочки Automatic в пункте Threshold, а вот ползунком в пункте Sensitivity of the processing регулируем задаваемый уровень (увидеть результат перед применением к странице можно, нажав кнопку Preview). Если полученный эффект полностью удовлетворяет вашим амбициям — смело жмите «ОК» и переходите к следующему пункту. А следующий пункт — преобразование картинки из градаций серого цвета в чёрно-белую палитру. Для этой цели будем использовать инструмент Binarization. В зависимости от алгоритма преобразования, бинаризация бывает пороговой, адаптивной, энтропийной и тому подобное. В нашем случае имеет место первый вариант, а именно — бинаризация пороговая. Порогом бинаризации называется двоичное значение номера серого цвета, всё светлее которого становится белым, а всё темнее — чёрным. Это теория. Приступим к практике. Не снимая выделения с файла, обрабатываемого по вышеописанному методу, щёлкаем по узлу Binarization. Появляется меню с двумя ползунками — Details Filtering и Depth. Регулируем первый (и пока не двигаем второй), одновременно посматривая в окошечко Quick Preview, где в увеличенном масштабе отображаются изменения, происходящие с текстом. Нажав кнопку Preview, можно увидеть и всю страницу целиком. Ваша цель — получить оптимальное соотношение между читаемыми символами чистого текста и мусором, оставшимся/образовавшимся после обработки изображения инструментом Lighting correction. Очень хороший результат получается, если обрабатываемые страницы содержат только текст или несложные схемы. Если же речь идёт о полутоновых картинках — здесь нам и понадобится второй ползунок Depth. Методика подбора: изменяя взаимное положение ползунков, следить за состоянием картинок до получения приемлемого результата. Предчувствую, что читатели могут подумать: а к чему столько мороки, ведь тот же IrfanView умеет быстро конвертировать любую картинку в чёрно-белый TIFF. Уметь-то он умеет, да качество при этом страдает. Вся разница в том, что там порог бинаризации жёстко фиксированный и намертво «прошит» в коде программы, то есть ни о каком визуальном подборе даже речи не идёт. Теперь осталось устранить перекос страниц (если он есть) и убрать мелкий мусор. Для этих целей и предназначены команды Deskew и Despeckle. Первая автоматически устраняет перекос (притом можно задать точность определения перекоса до десятой доли градуса и выравнивать как по положению текста в целом, так и по левому/правому краю), а вторая убирает мелкий мусор — соринки, пятнышки и тому подобное. Как показала практика, команду Despeckle нет смысла использовать на цветных изображениях и Greyscale (результат практически нулевой), а также на страницах плохого качества (могут исчезнуть части отдельных букв, точки и запятые). Кстати, в программе есть продвинутый вариант функции устранения перекоса — Geometrical Correction. Его имеет смысл использовать, если автоматическая функция Deskew не дала ожидаемых результатов. Как видно на скриншоте, данная опция позволяет устранить даже сложные геометрические искажения вручную, с ювелирной точностью.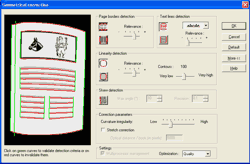
Чтобы осуществить пакетное конвертирование, нужно выбрать все страницы в пакете (меню Edit > Select all или Ctrl+A) и проделать все вышеописанные пункты. Ну а можно записать свои действия в макрос, а уже макрос применить ко всем выделенным страницам. Для этого выбираем Restoration-Scripts > New Script и жмём красную кнопочку «Запись» на панели инструментов. Производим над картинкой всю последовательность действий, затем нажимаем на кнопку «Остановить запись». Теперь этот макрос можно запустить в любой момент на выбранных файлах. Он отображается в подменю пункта NewScript. После окончания пакетной обработки осталось только наш полуфабрикат сохранить для дальнейшей обрезки и подгонки. С этой целью направляемся в меню Book > Publish, указываем папку назначения, а также выбираем формат сохранения файлов (в нашем случае это G4-compressed TIFF, Сolor Range — binary). Жмём «ОК» и читаем дальше. Теперь дело за малым — правильно обрезать и разрезать страницы перед кодированием. Под словом «правильно» подразумевается ровно и одинаково для всех страниц. Здесь сразу следует сказать о разнообразии полученных после сканирования вариантов отображения картинок. Если книга небольшого размера, то отсканировать её удалось полным разворотом на две страницы. Если размер побольше — то получаем скан одной страницы + часть второй. Всегда старайтесь сканы редактировать так, чтобы на одну страницу в электронной версии приходилась одна в бумажном варианте. Что бы там ни говорили любители читать книги полным разворотом, но разворот можно оформить и средствами просмотрщика (тот же DjVuReader или WinDjView умеет отображать на экране одновременно две страницы). Теперь на передний план выходит легендарная, не побоюсь этого слова, программа SсanKromsator (далее SK) от bolega. Возможности данной утилиты просто отменные, можно даже писать книгу по тонкой настройке и особенностям различных режимов работы. Но я попробую остановиться на главном. Итак, наше «скан-сырьё» может быть либо двухстраничным, либо «полуторным». Механизм обработки примерно одинаков, но для большего удобства рекомендую в полуторных сканированных страницах произвести разделение на право- и левосторонние (если правильно называть файлы при сканировании, то это будут чётные и нечётные файлы) и разложить их по разным папкам. Запускаем SK и загружаем туда все чётные файлы (меню File > Open). В левом вертикальном узком окне отображается список загруженных файлов. Для начала следует запустить режим так называемого «чернового кромсания» (Draft kromsate), чтобы маркеры попытались расставиться сами, в соответствии с интеллектуальным алгоритмом распознавания границы текста (особенности этой процедуры и связь её результатов с цветом полоски-маркера смотри ниже). В меню Edit > Draft kromsate видим диалоговое окно, где уже должна быть галочка напротив Split (это чтобы разрезать картинку на две части, в случае «полуторок» галочку лучше убрать). Жмём «ОК» и после нам останется только подправлять расположение маркеров-резаков мышкой (если где-то что-то выступает за край или обрезается). Резаки запоминают последнюю позицию, поэтому, как правило, при переходе с файла на файл даже не потребуется подвигать резак. Сами маркеры представляют собой синие или малиновые полоски. Синие — ограничители участка, внутри которого будет происходить основной процесс обработки, соответственно, и линия отреза обычно параллельна маркеру. Резак же малинового цвета — это средство ручной корректировки (он режет именно по тому месту, над которым находится), применимое, в основном, в случаях отстоящих далеко от основного текста номеров страниц, параграфов, кусочков строк и т. п. Чтобы упростить себе жизнь, щёлкаем правой кнопкой мыши по каждому резаку (левый-правый, верхний-нижний) и в контекстном меню выбираем Copy current position to…, где в выпадающем меню отмечаем all down (на случай, если мы хотим перенести расположение с первого файла на остальные), аll marked (на все помеченные) или all alternate (на все, за исключением помеченных). Затем кнопочкой «W» листаем файлы в списке (Q — листать назад) и проверяем, чтобы маркеры находились на нужных местах. Теперь для сохранения настроек нам понадобится зайти на закладку Options2 главного окна и в выпадающем меню Cutters State выбрать Only cut, так как всё, что нужно, мы уже почистили и выровняли. Жмём кнопку на этой же странице (если вы начали с последнего файла — то Apply up to current — применить ко всем непомеченным файлам вверх от текущей). Теперь идём на закладку Files и устанавливаем путь к папке, где будут находиться наши обработанные файлы — пункт Output Dir. Пункт DPI я рекомендую выставить в режим Original (если сканы выполнялись с разрешением 300 dpi и не требовалось его увеличивать). Сolor тоже ставим Original. Чтобы опция была применена ко всем страницам, при выборе удерживаем Ctrl. Аналогично — при выборе остальных опций, которые применяются ко всем страницам сразу. Если во время автоматического редактирования отрезаются номера страниц, то можно на закладке Options2 увеличить чувствительность текста (text sensitivity). Если на выходе требуется получить не одиночные страницы, а развороты, то в задании всё равно нужно выполнить независимое выравнивание половинок разворота, но на закладке Book включить опцию Merge pages after split. После того, как все страницы проверены на правильность расположения маркеров, смело жмём на кнопку Process! и ждём результата. Затем повторяем методику для оставшихся страниц (чётных или нечётных). После завершения процесса обработки автоматически открывается окно ResultView, в котором можно увидеть полученный результат, и если что-то вышло не так, как хотелось — исправить. После каждого исправления и перехода на последующую страницу программа будет спрашивать о потребности в сохранении. Так, пошагово, можно проверить каждый скан. Отмечу, что SK присваивает файлам свои порядковые номера, поэтому без пакетного переименования не обойтись. Проделывается это, опять же, с помощью IrfanView для каждого типа файлов отдельно, полученные картинки объединяются в одну директорию, а дальше можно приступать к следующему этапу обработки.
Часть 3
Этап третий: кодирование
Это, наверное, один из самых несложных этапов. Всё, что нам нужно — это просто открыть в Document Express Editor картинку с первым порядковым номером, а далее, щёлкнув по ней правой кнопкой мыши, выбрать пункт «Добавить страницы после». Выбираем последнюю картинку, зажимаем Shift, выбираем вторую по счёту. Жмём «Открыть». После того, как все страницы добавились в проект, мы вплотную подошли к процессу рождения новой электронной книги. Жмём Файл > Сохранить. В открывшемся диалоговом окне указываем название, снимаем галочку OCR (ниже объясню, зачем), выбираем профиль. На выбор предоставляются следующие: чёрно-белый, нормальный, электронный, рукопись, фотография, рисунок, карта. Для наших целей подойдёт либо вариант «нормальный», либо вариант «чёрно-белый», особенно, если в книге преобладает текст и в дальнейшем планируется отдельная обработка имеющихся рисунков и фотографий. Закладка «Качество текста». Опытным путём установлено, что при соблюдении вышеописанной методики подготовки материала при выборе режима «агрессивный» размер полученной книги уменьшается практически в три раза, по сравнению с профилем «без потерь», без заметного ухудшения качества и читаемости. Хотя в случае, если бинаризация не была произведена, имеет смысл использовать вариант «без потерь» или «практически без потерь». И, наконец, выбор разрешения. Диапазон — от 100 до 600 DPI. Вне зависимости от разрешения, с которым производилось сканирование, рекомендую выходное разрешение устанавливать на допустимый максимум (600). Читаемость определённо улучшается, да и размер, как ни странно, оказывается меньше. На этом всё. Сохраняем книгу. По истечению некоторого времени книга будет готова. Теперь самое время поправить испорченные низким количеством отображаемых цветов рисунки (я специально не затронул этот вопрос, когда речь шла о предварительной подготовке). Ищем файлы с картинками, качество которых нам не нравится, и удаляем их (опять же, выбрав пункт «Удалить» в контекстном меню правой кнопки мыши), но при этом желательно запомнить точное местоположение удалённой страницы. Затем берём заранее обрезанный цветной скан (об этом я говорил ещё в самом начале статьи) и вставляем его на место удалённой страницы. И так для всех требуемых случаев. Сохраняем обновлённый документ, но при выборе профиля вместо «чёрно-белый» устанавливаем «фотография». Кстати, так не мешало бы поступать в случае обложки для всех без исключения книг. Можно, конечно же, эти действия проделать и другим способом, с помощью всё той же программы ScanKromsator, просто во время расстановки резаков, обведя картинку или фотографию выделением и щёлкнув правой кнопкой мыши, выбрать Exclude Region для цветных рисунков или Exclude and Mark as dither region для градаций серого. А можно просто править полученные TIFF-ы в «Фотошопе», вручную вставляя фотографии. Здесь каждый волен выбирать сам, в зависимости от предпочтений. Кстати, в последних версиях SK (5.81 или 5.91) появилась возможность сохранять цветные иллюстрации в отдельные файлы, которые потом нужно объединять с текстовым чёрно-белым содержимым. Делается всё это с помощью пункта меню Магk as picture zone, изображённого в виде стилизованной картинки. Двойной щелчок по выделенной области открывает меню, в котором можно выбрать глубину цвета (по умолчанию используются градации серого) и/или изменить разрешение.
После обработки выделенные сегменты лучше всего объединить с исходными изображениями (если, конечно, вы не планируете их дополнительно редактировать в Photoshop). Делается это в меню Zones > Picture Zone > Merge zones.
Этап четвёртый: OCR
Optical Character Recognition — оптическое распознавание знаков в свете идеологий DjVu, представляет собой вложенный текстовый слой. Вещь эта немаловажная для любой книги, претендующей на звание высококачественной, да и самому удобнее с такой документацией работать, будь то простое копирование в буфер обмена текста или возможность полноценного поиска. Вот здесь то нам и пригодится старый добрый ABBYY FineReader любой версии (желательно не ниже 7). Но участие его косвенно. А главным героем этого этапа является совершенно бесплатная программа DjvuOCR 2.42 от болгарского программиста Gencho, которая уже работает и с 9-й версией пакета FineReader. Итак, берём изображения, из которых мы делали нашу книгу (надеюсь, вы их не удалили), и загружаем в FineReader любой версии (не обязательно использовать зарегистрированную версию, программа приемлет и результат обработки Try&Buy), где распознаём все страницы в пакетном режиме. По окончании сохраняем пакет. Теперь запускаем DjvuOCR, в главном окне программы щёлкаем по значку, подписанному как Manual made OCR manager. Здесь же в пункте FineReader Project directory выбираем каталог с проектом, сохранённым выше, в Output OCR text file указываем путь к любому текстовому файлу, расположенному в каталоге проекта. Теперь осталась самая малость — поставить галочку около пункта Burn DjVu file и вслед за этим выбрать созданную ранее книгу, чтобы утилита внедрила туда свежеполученный текстовый подслой. Жмём кнопку Process. Данный способ выбран по той причине, что в нём качество распознавания гораздо лучше, чем у OCR-менеджера, встроенного в Document Express Editor. Поэтому я и не советовал при сохранении DjVu-книги ставить галочку напротив пункта OCR. Поддержка небольшого количества языков и отвратительное качество распознавания без возможности правки полученного результата — вот характерная черта продукта от LizardTech. Кстати, помимо своего прямого назначения, утилита DjvuOCR может использоваться и для пакетной декомпиляции книги из DjVu в картинки (tif/jpg/bmp). Это может понадобиться для того, чтобы распознать и сделать на их основе OCR-слой. Теперь переходим к заключительному этапу нашей эпопеи «борьбы за качество электронных книг».Этап пятый: оглавление и гиперссылки
Согласитесь, не особенно удобна навигация по документу, содержащему под тысячу страниц без оглавления. Сделать его можно по-разному. К примеру, в неоднократно уже упомянутом Document Express Editor выбираем на панели инструментов кнопку «Прямоугольная гиперссылка», обводим требуемый участок текста и автоматически выскакивает окно свойств новой гиперссылки, где можно указать и номер страницы, на которую будет нацелен переход. Работа весьма утомительная. Есть способ попроще. Называется он DjVu Hyperlinks Editor. Для создания корректного оглавления к документу должен быть обязательно (!) прикреплён текстовый слой (про что говорилось выше, во время разбора программы DjvuOCR). Далее запускаем программу и указываем начальную и конечную страницы диапазона, для которого будет создано оглавление. Делается это напротив строки «Страницы с…». Указываем номера, где «1» — означает первая страница после окончания оглавления. Выбираем тип оглавления («Содержание» или «Алфавитный указатель»). «Алфавитный указатель 1» — гиперссылка ставится на всю строку. «Алфавитный указатель 2» — гиперссылка ставится только на номер страницы. Выбираем стиль оформления содержания (на ваш вкус). Нажимаем кнопку «Добавить» и выбираем DjVu файл. Жмём на кнопку «Создать» и вот теперь-то можно (и даже нужно) книгу свою выкладывать на сайтах вроде nova.cc (ну и периодически почитывать комментарии с благодарностями за прекрасно выполненную работу). Кроме того, если даже сканера у вас нет, можно принести пользу, просто переделывая некачественно созданные книги.Вознаграждение
В среднем, на создание одной книги (размером в 400–500 страниц) в хорошем качестве уходит полдня. И если сначала это занятие кажется довольно утомительным, то постепенно появляется даже некоторый азарт. И, сделав один раз качественную копию цифровой книги, постепенно появляется желание сделать ещё одну и ещё одну, и ещё. Плюс ко всему, если свой «шедевр» залить, к примеру, на depositfiles.com, то можно будет зарабатывать копейки за каждое скачивание. Так что польза получается обоюдная: и создателю, и читателям.* * *
На этом всё. Удачи вам в этом нелёгком деле качественного книгопечатания. Ждём новых книг, хороших и разных.Фотоаппарат вместо сканера
После публикации моей статьи, посвящённой проблеме создания качественных цифровых копий книг, мне пришло довольно большое количество писем. Люди спрашивают, почему я использовал сканер, а не широко распространённые цифровые камеры. В этой статье я исправлюсь и расскажу о том, как с помощью обычного фотоаппарата создавать «шедевры», ничем не уступающие копиям, созданным на сканере. Отчасти это обусловлено и тем, что сканер в наши дни — вещь довольно редкая, а цифровая камера есть практически в каждой семье. Главные требования к процессу «сканирования» цифровой камерой — отсутствие дрожания рук и хорошая освещённость. Что касается первой проблемы — решается она с помощью штатива. Если вы свято уверены в нерушимой крепости своих рук, то скажу, что после 150–200 отснятых страниц руки начинают дрожать даже у кандидата в мастера спорта по армрестлингу. Так что рекомендую потратить $30–50 и купить что-нибудь из продукции Rekam или Slik. Если штатива нет, остаётся только искать точку опоры и фиксировать фотоаппарат на ней. Однако в этом случае будет очень большой процент брака. Если вы поставили камеру на штатив, то логично будет автоматизировать процесс съёмки, подключив фотоаппарат к компьютеру. Он будет снимать автоматически, а вы — только переворачивать страницы. Для фотоаппаратов Canon (именно такой у меня) лучшим вариантом являются бесплатная программа Cam4You (alkenius.no-ip.org/Cam4you_remote/Cam4you_remote_2000.exe) или триальная Сam2Com (www.sabsik.com/Cam2Com/Cam2ComM.zip). Рекомендую при использовании последней скачать и программу для автоматизации процесса съёмки C2C Auto (www.sabsik.com/Cam2Com/C2CAuto_4_1_2_4.zip). Теперь достаточно только жёстко зафиксировать камеру на штативе и подобрать подходящие параметры на компьютере. Готовьтесь к трудностям. Во-первых, придётся всё время придерживать рукой переворачиваемую страницу, дабы в момент съёмки она не откатилась на исходную позицию. Во-вторых, нужно повозиться с установкой ножек штатива, чтобы в поле зрения камеры попадала максимальная площадь сканируемой книги. Делать это придётся, либо наклоняя камеру под небольшим углом (как бы нацеливаясь на перспективу), либо располагая штатив под углом (удлинив или укоротив одну из ножек). Вторым пунктом у нас стоит освещённость. В большинстве случаев, если фотографируете днём около окна — дополнительных источников света не потребуется. Но хорошее дневное освещение и ровный подоконник не всегда доступны. Поэтому самый распространённый вариант — использование встроенной вспышки. В конце концов, при возможности, можно использовать внешнюю настольную лампу. Направлять свет на книгу всегда нужно от фотографа. Для этих целей неплохо подходят переносные люминесцентные лампы в пластмассовых корпусах. Что касается настроек цифрового фотоаппарата — установленных по умолчанию, как правило, достаточно. Иногда, правда, может потребоваться отказаться от автоматического режима фотографирования в пользу режима с приоритетом выдержки (shutter priority), где оптимальным значением будет 1/50. Ну а когда всё, что можно, сфотографировали — пришло время для обработки. Фотографии с цифровой камеры имеют довольно неприглядный вид. Здесь и неровные края, и выпуклость страниц около корешка книги, и окраска страниц во все цвета радуги (в зависимости от освещения комнаты). В общем, работы уйма. Начать предлагаю с разрезания двухстраничных картинок на одинарные. С этим справляется уже знакомый нам ScanKromsator (SK, особенности работы с ним были описаны во второй части статьи «Цифровое книгопечатание» в «КВ» № 36/2008). Загружаем фото и обрабатываем. Единственное, на чём хотелось бы остановиться, — в меню Files выходной формат выставляем TIFF LZW Compress, Color — Original, DPI — Original. После обработки получаем постраничный материал. Для наглядности приведу пример картинки до обработки SK и после (рис. 1).

Рис. 1
Как можно заметить, программе мы просто поручили выполнить разрезание страниц и добавление автоматических полей (чтобы не так заметно было сильное искривление страниц). Теперь не мешало бы убрать бледный фон и привести в порядок размытости букв. Для этой цели мы будем использовать популярный графический пакет PhotoShop (подойдут любые версии, начиная с 6-й). Он позволяет автоматизировать рутинные действия по обработке фотографий с помощью командных файлов или скриптов. Чтобы начать использовать данную возможность пакета, включаем меню Actions (в пункте Window панели инструментов Photoshop) или просто нажимаем в активном окне редактора комбинацию клавиш ALT+F9. Появляется панель Actions, где, нажав маленький кружок со стрелкой в правом верхнем углу, выбираем пункт «New Action» и как-нибудь его называем — к примеру, «черновая обработка». Теперь открываем любую из наших «покромсанных» страниц и нажимаем внизу панели Actions кнопочку Play. Запись началась. Впоследствии записанные действия можно будет применить ко множеству страниц, на этом остановимся попозже. Итак, последовательность действий такова: 1. Image-Convert to GrayScale (переводим фото в режим градаций серого). 2. Image-Adjustments-Levels, жмём кнопку Auto, тем самым утолщая тонкие линии на фото. 3. Filter-Other-HighPass (значение Radius = 4.7 пиксела) — выделяем резкие контрастные переходы, которыми и являются границы букв, а также чистим мелкий мусор. 4. Image-Adjustments-Brightness & Contrast (яркость ставим около +45, контраст — около +70) — добиваемся максимальной читаемости текста. 5. Filter-Blur-GaussianBlur (Radius — 0.1 пиксела) — сглаживаем неровности по краям букв. 6. Image-Adjustments-Brightness & Contrast (контраст доводим до +90). 7. Image-Adjustments-Threshold (Threshold Level = 125–140) — оставляем на картинке только два реальных цвета — чёрный и белый, просто отбрасывая остальные (но считается она по прежнему 8-битной). Сохраняем картинку в формате TIFF LZW Compress и нажимаем кнопку Stop на панели Actions. Макрос записан (рис. 2).

Рис. 2
И, как водится, напоминаю — все значения даны для ориентира. Точно подобрать параметр можно только на конкретных фотографиях. Поэтому трижды проверьте установки конкретно на своём черновом материале. Итак, возвращаемся к нашим картинкам. После обработки фильтрами Photoshop картинка выглядит примерно так, как на рис. 3.

Рис. 3
Теперь осталось только применить записанную и отлаженную последовательность действий ко всем остальным фотографиям. Сделать это можно различным способами, но я рекомендую облегчить себе жизнь и создать командный файл. В PhotoShop выбираем меню File — Create Droplet. Программа создаст исполняемый exe-файл для пакетной обработки. В настройках файла «Save Droplet In» выставляем «Рабочий стол». Теперь просто берём и в Проводнике перетаскиваем папку с нашими картинками на иконку созданного файла droplet-a и наблюдаем, как запустившийся Photoshop обрабатывает файлы. На одну картинку уходит порядка 3–5 секунд. Обработанный материал складывается в папку Out. Таким образом, однажды создав командный файл, в дальнейшем можно использовать его для сотен книг. Когда конвертация завершена, загружаем полученные файлы в Book Restorer (BR) и применяем к ним инструмент Geometrical Correction. Опция Deskew с фотографиями практически не работает, поэтому её и нет смысла использовать, как на начальной стадии — в SK,так и в BR. Выделяем все страницы (Ctrl + A) и щёлкаем по нужному пункту меню Restoration (рис. 4).
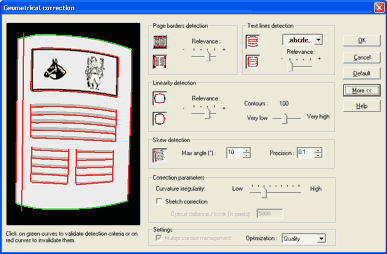
Рис. 4
В появившемся диалоговом окне нужно последовательно щёлкнуть по всем подсвеченным зелёным цветом частям текста и заставить их «покраснеть», т. е. включить функции определения искривления для боковых сторон страницы. Здесь же, при нажатии кнопки «More», можно вручную установить параметры чувствительности к линейным искривлениям около корешка книги. В принципе, установленные по умолчанию значения позволяют довольно неплохо справляться с большинством дефектов. Но уж если ваш случай довольно серьёзен, то остаётся одно — действовать методом научного тыка и проверять работоспособность фильтра на тестовой картинке. Осложняет положение и тот факт, что функция быстрого просмотра для данного инструмента отсутствует. Не исключено, что придётся несколько раз менять установленные параметры. Параметры чувствительности желательно установить на максимум. Для определения перекоса ставим точность — 0.01 градуса. В закладке Optimization выбираем Quality. После того, как настройки приведены в порядок, жмём ОК и наблюдаем за работой программы (рис. 5).
Рис. 5
Возможно, страницы с сильным перекосом придётся несколько раз пропускать сквозь фильтр геометрии, поочерёдно увеличивая чувствительность в параметрах детектирования. После выравнивания картинок осталось сделать самую малость — почистить края от переплётов или пальцев, попавших в кадр. Сделать это можно с помощью панели ретуши — Retoutch Toolbar в программе BR, но есть более продвинутый вариант — в версии Book Restorer, начиная с 4.2.1.0, появился инструмент панели Restoration под названием «Маскировка пальца», который предназначен специально для удаления артефактов по боковым краям страницы. Ну а в дальнейшем, просто выделив все страницы, можно легко и просто автоматизировать процесс ретуширования краёв. Теперь наши картинки осталось только сохранить в формате TIFF G4 Compress (binary) через меню File-Publish. Ну а дальнейшие действия подробно были описаны в «КВ» № 38/2008, так что заострять на них внимание не стоит. P.S. Возможно, у кого-то возникнет резонный вопрос: а почему же в этот раз обошлось без интеллектуальной бинаризации, которая раньше ставилась чуть ли не главным достоинством программы BookRestorer? Дело всё в том, что обработанные Photoshop рисунки в бинаризации не нуждаются и без потерь могут быть сохранены в битональном TIFF.
Автор выражает благодарность Сергею Былю и Роману Ногободсу за предоставленную цифровую технику и моральную поддержку.
Книга за 5 минут
Моему младшему брату Геннадию, студенту ВГАВМ посвящается…Цифровая книга победно шествует по миру. Не может не радовать тот факт, что если вчера еще невозможно было найти даже упоминание о книге, то сегодня уже появилась пара-тройка электронных копий (пусть и источник их возникновения, а значит, и качество, один и тот же). Практически все доступные ныне модели читалок электронных книг (PocketBook, lBook, ORSiO) умеют работать с форматом Djvu. Ну а разработчики тех, которые пока не умеют, в ближайшее время грозятся исправить код своих прошивок и возможность эту добавить. Недалек тот час, когда djvu станет признанным международным стандартом для научно-технической литературы и сменит громоздкий PDF. Читают книги многие, а создавать собственные почему-то спешат лишь единицы. И несмотря на обилие статей-руководств, книги почему-то получаются низкого качества, с «душком» продукта, сделанного для проформы. С одной стороны, когда книг много и нужно оперативно их перевести в электронный вид — некогда думать о качестве, лишь бы побыстрее отсканировать да скормить сканы компилятору. Но, с другой стороны, когда приходится такой книгой пользоваться — тогда уж поздно проклинать кого-то и посыпать голову пеплом. Спасение утопающих — дело рук самих утопающих. Возможной причиной наплевательского отношения к создаваемым книгам может быть и то, что масса сил расходуется на осваивание программ-редакторов вроде ScanKromsator (далее SK), которые, несмотря на обилие функций, далеки от пользователя и к тому же зачастую работают с переменной стабильностью. Кое-кому преградой может стать размер дистрибутивов программ. Итак, дано: необходимость быстрого создания десятка копий бумажных книг, без сканера и ПК с комплектом установленных программ. Для соответствия всем требованиям было решено использоватьцифровой фотоаппарат Canon PowerShot A700 и набор программ, работающих со съемного USB-накопителя и не требующих установки. Кроме всего прочего, особенный акцент делался на малом размере дистрибутивов программ. Да не сочтет глубокоуважаемый читатель мои слова за рекламу, но фотоаппарат этот отменно проявил себя на поприще экспресс-фотографии бумажных книг. Это при том, что съемка велась с рук, без всяких дополнительных устройств вроде штативов или фиксирующих ремешков. Освещение тоже использовалось естественное — солнечный свет, который попадал в помещение через окно. Так что в условиях, которые раньше можно было считать совершенно неприемлемыми для работы, с техникой Canon все прошло просто замечательно, с минимальным количеством неудобств. После того как книга успешно сфотографирована, настает черед программ пост-обработки. До сих пор в роли основного «разметочного» инструмента выступала уже упомянутая программа SK, известная сложностью освоения, поскольку перед тем, как запустить пакетную установку, уйма времени уходила на то, чтобы выставить настройки программы в требуемые параметры. Зачастую, из-за забывчивости, приходилось обрабатывать фотографии еще раз. Так дальше продолжаться не могло и неизвестно чем бы закончилось, если бы не всплыл у меня в памяти разговор с товарищем, поклонником Unix-оподобных операционных систем. Речь шла о том, что в среде Linux совершенно нет адекватных средств для создания djvu-книг. Так предполагал я, а друг разрушил все мои предположения, познакомив с программой Scan Tailor. Поскольку программа эта новая и совершенно не изученная, на особенностях ее рабочего интерфейса я остановлюсь подробнее. Утилита Scan Tailor (далее — ST; официальный сайт — scantailor.sourceforge.net) представляет собой инструмент для обработки отсканированных страниц, основной особенностью которого является интуитивно понятный пользовательский интерфейс. Программа является свободным ПО и распространяется под лицензией GPL. Имеются версии как для Windows, так и для GNU/Linux. Самое интересное, что уже практически два года проект этот держится исключительно благодаря одному единственному человеку — Иосифу Арцимовичу. Работать с программой на удивление просто. Участие пользователя сведено к минимуму. После запуска программы видим окно, в центре которого выскакивает табличка с двумя пунктами: «Новый проект» и «Открыть проект». Так как мы начинаем с нуля, щелкаем по первому пункту. Сразу же предлагается определиться с рабочим каталогом. Щелкнув по кнопке «Обзор» напротив пункта «Директория ввода», выбираем папку, в которой хранятся наши необработанные фотографии. По умолчанию, обработанные файлы будут сохраняться в подпапке out родительской директории. Если вы хотите изменить место, в котором будут сохраняться рисунки после обработки, — сделать это нужно во время создания проекта (щелкнув по кнопке «Обзор» и задав нужное местоположение). Если выбранная директория содержит графические файлы подходящего формата — они немедленно станут видны в окне «Файлы в проекте». Стоит отметить одну не совсем приятную особенность программы ScanTailor. После создания проекта удалить из него файлы не представляется возможным. Поэтому если в выбранной вами директории присутствует что-то лишнее, лучше всего файлы эти выделить (правым кликом мышки, с зажатой клавишей Ctrl) и, нажав на кнопочку «<<», перенести в раздел «Файлы не в проекте». Возможности предпросмотра нет, поэтому определиться с тем, что нужно обрабатывать, а что нет, лучше всего в Проводнике Windows, выбрав режим просмотра «Эскизы страниц», запоминая (а лучше записывая) названия требуемых фотографий. Нажимаем ОК и ждем, пока программа сформирует новый проект. В случае работы со страницами, полученными с цифрового фотоаппарата, может потребоваться изменение стандартного разрешения (для большинства цифровых мыльниц значение это равно 72 DPI, что, безусловно, недостаточно для создания качественной цифровой книги). Поэтому щелкаем по пункту с размером наших фотографий, в меню DPI выбираем значение 300×300 и нажимаем кнопку «Применить». Как показывает практика, для абсолютного большинства пользователей такого разрешения будет достаточно. Ничего страшного не случится, если выбрать и 600×600, но придется мириться с увеличением размера конечного продукта. После того, как разрешение приведено в порядок, рабочее окно программы принимает вид как на рисунке 3. В окне слева имеется шесть пунктов, по количеству доступных инструментов обработки: 1. Исправление ориентации 2. Разрезка страниц 3. Компенсация наклона 4. Полезная область 5. Макет страницы 6. Вывод После щелчка по любому из пунктов ниже панели инструментов становится доступным окно параметров каждого инструмента. Справа от названия инструмента видна круглая кнопка, похожая на кнопку Play WindowsMediaPlayer. Этой кнопкой запускается пакетный режим обработки файлов. По умолчанию страницы обрабатываются в соответствии с изначально заложенной в программу схемой. Если вы каким-то образом модифицировали исходную картинку (повернули, разрезали или расширили поля) и хотите в дальнейшем применить тот же шаблон для всех остальных фотографий — придется воспользоваться меню «Область применения». Функция эта в том или ином виде присутствует в параметрах каждого из инструментов и может состоять из следующих пунктов: • Применить только к этой странице • Применить ко всем страницам • Применить к этой странице и всем последующим • Применить к каждой второй странице в диапазоне • Применить к выделенным страницам По умолчанию обработка проходит по третьему сценарию. Пункт «Применить к каждой второй странице в диапазоне» укажет выбранному инструменту на то, что нужно обрабатывать каждую вторую фотографию, то есть либо каждую четную, либо каждую нечетную, в зависимости от того, четная или нечетная текущая страница. Ну и последний пункт позволяет применить инструмент к страницам, выделенным пользователем.

Теперь пора перейти непосредственно к описанию рабочих инструментов. Первым у нас идет пункт «Исправление ориентации». На данной стадии можно повернуть скан на угол, кратный 90 градусов (90/180). Стадия эта ручная, то есть программа не умеет сама определять правильную ориентацию сканов — это должен сделать пользователь. Это также означает, что запускать пакетную обработку на данной стадии бесполезно — будет пустой проход. Кнопки с желтыми стрелками поворачивают скан на 90 градусов по или против часовой стрелки. Зелёная стрелка показывает, куда в данный момент повернут скан. Кнопка «Сброс» возвращает скан в исходное положение — зеленая стрелка будет указывать вверх. Вторым инструментом обработки является «Разрезка страниц». На этой стадии определяется, нужно ли, и если нужно, то как, разрезать скан. Тип разреза слева направо: • Одностраничный скан без каких-либо частей соседней страницы. • Одностраничный скан, в который попала часть соседней страницы. • Двухстраничный скан. Тип разреза определяется автоматически, хотя может быть задан и вручную. Разделительная линия также может определяться автоматически или задаваться вручную, но ее нельзя применить к другим страницам. В случае если выбран второй тип разреза, появится возможность вручную указать полезную область: слева или справа от линии разреза. Далее у нас идет «Компенсация наклона». На этой стадии определяется угол, на который надо повернуть страницу, чтобы строки стали строго горизонтальными. Поскольку компенсация делается простым вращением, то искривления, присущие сканам с цифрового фотоаппарата, исправить нельзя, делать это нужно с помощью BookRestorer (далее BR), о чем читайте ниже. Угол наклона определяется автоматически, но имеется возможность задать его и вручную. Изображение можно вращать, перетаскивая мышкой рукоятки, которые имеют форму шариков и расположены по краям. Здесь можно явно задать угол поворота в градусах. Положительные углы будут вращать изображение против часовой стрелки, отрицательные — по часовой стрелке. Для тонкой подгонки угла удобно кликнуть мышкой по текстовой части поля ввода угла, после чего использовать колесо мыши для его подгонки. Одним из самых важных инструментов является «Полезная область». На этой стадии определяется область с «полезным» содержанием (залито цветом). Нужен этот пункт для того, чтобы определить размеры страницы на выходе. К полезной области будут добавлены поля, и внешняя граница этих полей как раз и задаст размеры выходного файла. Кроме того, автоматически удаляется весь мусор с краев и линии сгиба (раньше этой работой приходилось заниматься вручную, с помощью инструментов все той же BR). В большинстве режимов поля заливаются белым. Если область определилась неверно, можно поправить ее вручную, потянув мышкой за ее край. Бывает также, что на странице, где совсем нет полезного содержимого, ST все равно находит полезную область, или, наоборот, не находит там, где она есть. В таком случае можно вручную создать / удалить область, кликнув правой кнопкой мыши по изображению и выбрав нужный пункт меню. Предпоследний инструмент — «Макет страницы». На этой стадии к полезной области добавляются поля. Есть два типа полей — жесткие и мягкие. Жесткие поля задаются пользователем и определяют физический размер страницы будущей книги. Жесткие поля можно регулировать визуально, перемещая линии-ограничители (внешнюю либо внутреннюю), а можно задать вручную, вписав требуемые числовые значения. Мягкие поля добавляются автоматически, чтобы довести размер страницы до размера других страниц. Здесь может возникнуть неприятный момент. Если в открытом проекте страницы имеют различный размер (к примеру, врезка формата A4 в книге форматом B5), то одна большая страница вызывает появление мягких полей у всех остальных страниц, если только для них не отключено выравнивание. Параметры выравнивания как раз и определяют, добавлять ли мягкие поля, и если добавлять, то с каких сторон. Поэтому рекомендую еще на этапе создания проекта разделить фотографии страниц с разными размерами и обрабатывать их тоже раздельно (помним, что удалить файлы из уже созданного проекта нельзя). Все параметры на стадии «Макет страницы» задаются вручную либо берутся значения по умолчанию. Таким образом в любой момент времени известны все параметры для всех страниц. Ну и, наконец, последний инструмент, который определяет внешний вид и формат создаваемых файлов, — «Вывод». На этой стадии создается и записывается на диск окончательное изображение страницы. Результат также отображается в центральной области программы. В отличие от других стадий, стадия «Вывод» становится доступной только после прохождения всеми страницами стадий «Полезная область» или «Макет страницы». Так происходит потому, что размеры страниц на выводе зависят друг от друга. Скажем, если попалась крупная страница, то у всех остальных наращиваются поля (о чем я уже упоминал при рассмотрении инструмента «Макет страницы»). Поэтому важно знать конечные размеры страниц, а узнать это можно, только обработав их упомянутыми инструментами. Наиболее важными параметром данного инструмента является возможность выбора режима кодирования страниц. Имеется три предустановленных значения: • Черно-белый • Смешанный • Цветной/Серый В черно-белом режиме программа интеллектуально бинаризирует (преобразовывает в однобитный цвет) фотографии. Опция «Удалять пятна» отвечает за ретуширование неугодных полос и точек. При плохом качестве съемки или большом количестве мелких деталей (особенно в математических формулах) могут затираться мелкие значки и индексы. Поэтому будьте бдительны. Смешанный режим используется для случаев, когда обычный текст присутствует наряду с полутоновыми картинками. Программа автоматически определяет наличие рисунка и сохраняет его в режиме, аналогичном Цветной/Серый. Текст сохраняется в однобитном цвете. Ну и, наконец, последний режим используется для всевозможных цветных иллюстраций и врезок. Лучше сразу поставить галочки около пунктов «Залить поля белым» и «Выровнять освещение». Эти опции нормализуют цвет фона, доводя его до белого, а также нормализуют контраст, увеличивая его в затененных областях. Применять данный режим имеет смысл в случаях, когда вам важна правильная цветопередача рисунка и хотелось бы видеть его в книге минимально измененным. После запуска пакетного конвертирования в рамках данного инструмента фотографии последовательно проходят все стадии, обрабатываясь в рамках установленных по умолчанию значений (если значения эти не установлены пользователем), и на выходе мы получаем уже практически готовые к компиляции в книгу материалы. А теперь посмотрим, как все это выглядит на практике. Первым делом загружаем наши фото из цифрового фотоаппарата в ST. Изменяем разрешение. Если страницы не требуют поворота, сразу переходим ко второму инструменту и разрезаем сканы на страницы. Пакетный режим можно запускать, только если вы уверены в том, что все фотографии однотипны. После окончания процедуры обязательно следует просмотреть сырой материал на наличие неправильной разрезки: там где нужно, двигая мышкой синюю линию резака, исправляем огрехи. Если все нас устраивает — переходим сразу к пункту «Полезная область» и повторяем режим пакетной обработки. В большинстве случаев программа сама правильно распознает область с текстом. Исключение составляют только слишком темные или пожелтевшие фотографии. Если вам пришлось работать именно с такой «продукцией» — самое время вспомнить материал, опубликованный в «КВ» № 9'2009. Там был описан алгоритм создания пакетного обработчика фотографий в Adobe PS. Повторяться не буду, но приведу последовательность операций, опираясь на которую, не составит труда скомпилировать свой обработчик (делать это нужно один раз). Для наших целей последовательность можно и нужно упростить, что никак не скажется на качестве конечной цифровой копии книги: 1. Image-Convert to Gray-Scale, переводим фото в режим градаций серого 2. Image-Adjustments-Levels, жмем кнопку Auto, тем самым утолщая тонкие линии на фото 3. Filter-Other-HighPass (значение Radius = 9.9 пиксела), выделяем резкие контрастные переходы, которыми и являются границы букв, а также чистим мелкий мусор 4. Save (значение TIFF LZW Compress), сохраняем картинку Создаем дроплет (File-Automate-Create Droplet…) и кладем его рядом с папкой, где хранятся изображения, ожидающие обработки. Чтобы выровнять уровни, достаточно папку с изображениями перетянуть на ехе-шник созданного пакетного файла-обработчика. Кстати, если сами вы определить потребность фотографий в «модернизации» не в силах, за вас это сделает ST, просто отказавшись правильно разрезать страницы или определять полезную область. Если такой факт имеет место быть — это сигнал, что без обработки PhotoShop не обойтись. Если все устраивает — переходим к финальной стадии работы с нашим «Портным» (Tailor в переводе с английского означает «портной»). Выбираем инструмент «Вывод» и прогоняем режим пакетной обработки на настройках по умолчанию. Затем проверяем страницы, где требуется — меняем формат вывода с «черно-белый» на «серый» или «цветной/смешанный». Последнее может потребоваться, если в книге присутствуют цветные или серые иллюстрации, которые программа не совсем адекватно преобразовала, тем самым испортив качество. После того, как все операции успешно проведены, в папке Out сохранились обработанные страницы. Вывод осуществляется в формат TIFF. В режиме «Черно-белый» — со сжатием G4Fax; в остальных режимах — со сжатием LZW. Приступаем к части второй. Так как предварительные сканы были получены с помощью цифрового фотоаппарата, то с высокой долей вероятности можно сказать, что 90 % страниц имеют перекос. Для его исправления воспользуемся проверенным инструментом — уже знакомой нам программой BR. Создаем новый файл проекта (Ctrl+N) и туда же загружаем файлы, обработанные ST. Выделяем все файлы (комбинацией Ctrl+A). В «Панели реставрации» (Restoration) программы щелкаем по значку «Коррекция геометрии» (Geometric Correction), где активируем все кнопки, кроме той, на которой изображен двухстраничный разворот. Жмем ОК, дожидаемся окончания операции. Теперь меню «Файл» — «Публикация» (File — Publish). Пришло время остановиться и оглянуться назад, подумать, а есть ли среди фотографий, прошедших обработку, страницы с иллюстрациями. Если таковых нет, то смело в графе «Тип файлов» выбираем «G4-compressed TIFF» и жмем «Сохранить». Если же цветные или серые картинки присутствуют, то компрессия в G4 может их безвозвратно испортить. Поэтому возвращаемся в основное окно программы, проматываем перед глазами список страниц и записываем (или запоминаем) номера страниц, которые нужно сохранять в формате «TIFF LZW-compressed» (для цветных рисунков) или «TIFF LZW-compressed 4bits» (для рисунков в градациях серого). Возвращаемся к меню публикации результатов. В закладке «Страницы» выбираем уже не «Все», а «Номера», где и вводим ранее записанные нами значения. Получается сохранение в два захода. В первый сохраняем цветные/серые иллюстрации (TIFF LZW), во второй — черно-белые (TIFF G4) или наоборот. Кстати, возможность работы со сжатым цветным TIFF-ом появилась только в последних версиях BR. Теперь дело за малым — сформировать и скомпилировать саму книгу. Процессом компиляции у нас издревле заведовал «монстр» от LizardTech — DocumentExpressEnterprise (далее — DEE), размер которого, в зависимости от ревизии, мог достигать 200 мегабайт. И самое обидное, что скачиваем-то мы, по большому счету, только дополнительные языки распознавания (чешский, немецкий и так далее), которыми не пользуемся. В ранних статьях я подробно описывал процесс добавления OCR-слоя и тогда уже становилось ясно, что с распознаванием лучше всего справляется специально для этого «обученная» утилита — ABBYY FineReader. Видимо, поняли это многие (кроме самих разработчиков) и поэтому из-под пера энтузиаста вышла урезанная версия DEE без дополнительных языков (так называемая Light Edition (dstu2204.narod.ru/djvu_old/DocExpress500_b16_plus.rar или dstu2204.narod.ru/djvu_old/DocExpress50016.rar или dstu2204.narod.ru/djvu_old/Editor6_LE_nt.rar). Обладает она всеми нужными функциями версии полной, прекрасно компилирует и декомплилирует djvu-книги. И размер уменьшился, ни много, ни мало, в сто раз. Скачать 2 мегабайта сегодня по силам даже энтузиастам dial-up Интернета (если таковые еще остались). Работа с утилитой облегченной аналогична работе с полной версией (которая подробно описывалась в «КВ» № 38 за 2008 год. Открываем первый файл («Файл» — «Открыть»), затем щелкаем по эскизу первой страницы и выбираем из контекстного меню «Добавить страницы после…». Выбираем файл, последний из списка, зажимаем Shift и щелкаем по файлу, идущему в списке вторым (первый у нас уже загружен в программу). Ждем, пока все файлы будут загружены, и выбираем меню «Файл» — «Сохранить как». Сохраняем файл со следующими параметрами: профиль — «нормальный», разрешение — «300 dpi», качество текста — «форсированный». После завершения кодирования останется самая малость — переименовать файл в соответствии с общепринятыми правилами систематизации. Но об этом немного позже. Хотелось бы упомянуть еще одну утилиту, которая при крошечном размере обладает всеми достоинствами DEE. Называется она Djvu Small (djvu-soft.narod.ru/soft/djvu_small_v0_3_4.rar) и представляет собой программный пакет для группового кодирования-декодирования в/из DjVu, составленный на основе программы DEE 5.0. DjVu Small имеет 3 режима работы, каждый из которых соответствует консольным утилитам для работы с djvu: • Документ —> DjVu (консольная утилита documenttodjvu) • Фото —> DjVu (консольная утилита phototodjvu) • Декодировать DjVu (консольная утилита djvudecode) Утилита documenttodjvu (и, соответственно, диалоговое окно «Документ —> DjVu») — утилита для пакетного кодирования чёрно-белых, серых и цветных графических файлов в форматах bmp, jpeg, jpg, gif, tiff, tif, pnm, ppm, pgm, pbm. Аналог предыдущей программы, phototodjvu, предназначен для пакетного кодирования серых и цветных графических файлов (в тех же форматах), но с улучшенным качеством. Ну и последний консольный обработчик, Djvudecode, служит для пакетного декодирования любых DjVu-файлов: одно- и многостраничных; содержащих чёрно-белые, серые и цветные изображения (при декодировании автоматически создаются файлы соответствующей битовой разрядности). В любом из режимов работы пользователь визуально формирует параметры кодирования, которые DjVu Small подаёт затем через командную строку на вход соответствующей консольной утилиты. Особых премудростей в работе с программой нет, просто открываем графические файлы, выбираем соответствующий режим работы, отмечаем профиль работы (значения аналогичны таковым в DEE) и жмем на кнопочку «Пуск». В результате получаем закодированный в djvu файл. Минимум лишних телодвижений — максимум функциональности. Графическая оболочка позволяет настраивать просто огромное количество различных параметров консольных утилит, но рядовому пользователю разбираться в этом смысла нет, так как описание функциональных особенностей тонкой настройки Djvu Small достойно отдельной статьи. Напоследок рекомендую назвать созданную вами книгу в соответствии с негласной номенклатурой, придуманной сообществом русскоязычных «книгопечатников» для облегчения систематизации книг в публичных библиотеках. Автоматизирует эту рутинную работу программа Name Creator (djvu-soft.narod.ru/soft/name_creator_v1_0.rar), которая генерирует название в соответствии с принятой системной классификацией djvu-книг. В дальнейшем соответствие единому стандарту облегчает процесс распространения книг через Интернет. Вот книга и создана. Возможно, на освоение технологии изначально уйдет много времени, но уже вторая-третья книга, при условии наличия достаточных машинных мощностей, будет укладываться в рамки «книжки-пятиминутки». Чтобы не быть голословным, скажу, что на ноутбуке Dell с 2 Gb оперативной памяти, жестким диском SATA2 7200 ppm и процессором Core2Duo P8500 обработка 300 двухсторонних фотографий книги формата B5 и конвертация их в электронную книгу занимает ~ 5 минут. Так что, «Революция уже началась! Присоединяйтесь!».
Автор выражает благодарность Судниковичу Сергею Федоровичу за предоставленное оборудование и аксессуары.
Последние комментарии
1 день 20 часов назад
2 дней 1 час назад
2 дней 3 часов назад
2 дней 4 часов назад
2 дней 5 часов назад
2 дней 6 часов назад