Программа обработки текста после сканирования AfterScan [Cadet Bigler] (fb2) читать онлайн
- Программа обработки текста после сканирования AfterScan 616 Кб, 10с. скачать: (fb2) - (исправленную) читать: (полностью) - (постранично) - Cadet Bigler
[Настройки текста] [Cбросить фильтры]
[Оглавление]
Программа обработки текста после сканирования AfterScan
В прошлой главе, рассматривая работу программы оптического распознавания текста FineReader, мы увидели, что текст после сканирования и распознавания нуждается в корректировке, и чем сложнее форматирование текста и чем больше его объем, тем больше усилий придется затратить, чтобы привести его к приемлемому для дальнейшей работы виду. Программа FineReader и текстовый процессор Word предоставляют мощные и разнообразные средства для решения этой задачи, но изрядную часть работы все-таки приходится делать вручную. Существует не очень известная в России программа AfterScan, которая в ряде случаев способна выполнить корректировку отсканированного текста автоматически. Эта программа может использоваться для обработки и правки текстов больших объемов, введенных с клавиатуры или полученных при помощи программ оптического распознавания текстов, причем для эффективной работы программы важно знать, каким именно способом получен текст. Авторы программы утверждают, что в ее основе лежат алгоритмы, позволяющие анализировать и исправлять ошибки и опечатки практически любых типов, причем в отличие от программы проверки грамматики Word, программа AfterScan может исправлять ошибки и опечатки самостоятельно. Рассмотрим эту программу более подробно. Программа AfterScan выпускается в четырех версиях AfterScan Express - shareware-версия для домашнего пользования; AfterScan Professional - для издательств и компаний; AfterScan Antique - для обработки текстов в старорусской орфографии и перевода его в современную орфографию; AfterScan Webmaster - для пакетной обработки большого числа документов, например, для обработки текстов, размещаемых на Web-сайтах. Различия между функциональными возможностями различных версий программ видны из таблицы:| Обработка текстов | Express | Professional | Antique | Webmaster |
| Обработка ошибок OCR | ♦ | ♦ | ♦ | ♦ |
| Обработка ошибок ручного ввода | ♦ | ♦ | ♦ | |
| Обработка старорусских текстов | ♦ | |||
| Перевод старорусских текстов в современную орфографию | ♦ | |||
| Чистка пунктуации | ♦ | ♦ | ♦ | ♦ |
| Чистка отступов и пробелов | ♦ | ♦ | ♦ | ♦ |
| Обработка латинских букв в русских словах | ♦ | ♦ | ♦ | ♦ |
| Восстановление специальных символов других языков | ♦ | ♦ | ♦ | ♦ |
| Восстановление римских цифр | ♦ | ♦ | ♦ | ♦ |
| Обнаружение сокращений и аббревиатур | ♦ | ♦ | ♦ | ♦ |
| Обнаружение математических и химических формул | ♦ | ♦ | ♦ | ♦ |
| Обнаружение HTML-тегов и скриптов | ♦ | |||
| Склейка слов с переносами | ♦ | ♦ | ♦ | |
| Склейка слов с отбивкой пробелами | ♦ | ♦ | ♦ | |
| Поиск новых слов в нескольких файлах | ♦ | |||
| Прочие функции | ||||
| Функция переформатирования текстов | ♦ | ♦ | ♦ | ♦ |
| Улучшенный диалог поиска и замены | ♦ | ♦ | ♦ | ♦ |
| Поддержка словаря пользователя и редактор | ♦ | ♦ | ♦ | |
| Ручная защита фрагментов текста от изменений | ♦ | ♦ | ♦ | |
| Сохранение Журнала вместе с документом | ♦ | ♦ | ♦ | |
| Пакетная обработка большого числа файлов | ♦ | |||
| Пакетная конверсия формата файлов | ♦ | |||
| Цена (на момент написания книги, для граждан СНГ, рублей) | 300 | 800 | 1500 | 2100 |
Программа AfterScan Express - условно бесплатная[1], ее оценочную версию, которая будет работать в течение 30 дней, можно загрузить с сайта программы по адресу: http://http://www.futura.ru/hg/ase51en.exe[2] (для английских текстов), размер файла - 2,9 Мб. На момент написания книги на сайте разработчиков была выложена сборка программы за номером 023. Установка программы никаких проблем не составляет. Достаточно запустить загруженный файл и следовать указаниям инсталлятора. Программа не требует настройки и готова к использования сразу после установки. Если вы приобрели версию программы Professional, Antique или Webmaster, то при первом запуске программы потребуется ввести личный идентификатор пользователя. Для версии Express это не нужно. Личный идентификатор пользователя - это число, которое используется для отслеживания версий грамматик программы AfterScan индивидуально для каждого пользователя. Грамматика - это один из файлов программы, который содержит информацию об ошибках и способах их исправления в соответствии со спецификой текстов, обрабатываемых пользователем. Авторы программы обещают, что при необходимости они могут откорректировать файл грамматики и выслать его пользователю. Личный идентификатор - это не серийный номер и не используется для защиты от копирования, хотя косвенно препятствует незаконному распространению программы. Интерфейс программы очень прост и содержит стандартные элементы окон Windows- программ: строку заголовка, строку меню, панели инструментов и рабочее поле программы. Программа умеет выполнять две основные операции, которые разработчики назвали OCR чистка (горячая клавиша <F8>) и переформатирование (горячая клавиша <F7>). Для чего нужны эти операции? Во-первых, при распознавании отсканированных текстов, особенно если оригинал отпечатан с невысоким качеством, бледным шрифтом с нечетким рисунком букв, происходит множество ошибок: буква «л» вставляется в текст вместо буквы «д», «с» вместо «е» или наоборот. Во-вторых, программы распознавания текста нередко «не понимают» особенностей расстановки букв в строке, к которым верстальщики прибегают, чтобы добиться равномерного размещения текста на странице. В результате возникают пробелы между последним словом фразы и точкой, что недопустимо, лишние пробелы «влезают» в текст, отделенный скобками, не к месту возникают заглавные буквы и пр. В-третьих, при наборе текста с клавиатуры нередко путают русские и английские буквы, имеющие одинаковое начертание: «с», «о», «х», «М». Если дело ограничивается созданием простого офисного документа, то это не беда, но если текст пойдет в электронный набор и планируется к размещению на Web-сайте, это может создать серьезные проблемы. В четвертых нередко попадаются тексты, набранные в старых текстовых процессорах с принудительной разбивкой абзаца по строкам и принудительными переносами внутри слов. Конечно, все эти ошибки можно исправлять и вручную, при работе с большими текстами или с большим количеством текстов затраты времени и сил могут отказаться просто нереальными. В решении этой проблемы AfterScan может оказаться хорошим подспорьем. Программа может работать в интерактивном, пошаговом режиме или полностью автоматически. Для работы с большим количеством однотипных документов в программе предусмотрен т.н. пакетный режим. Программа способна обрабатывать следующие виды текста: • Текст в современной орфографии после OCR (версии Express, Professional, Antique, Webmaster); • Текст после ручного набора или коррекции (версии Professional, Antique, Webmaster); • Текст без формул и адресов Интернет (версии Professional, Antique, Webmaster); • Дореволюционное правописание с переводом в современное (версия Antique); • Дореволюционное правописание с сохранением старой орфографии (версия Antique); HTML документ (версия Webmaster). Текст в современной орфографии (OCR). В этом режиме программа автоматически исправляет орфографические ошибки. Программа автоматически обнаруживает математические и химические формулы, повторяющиеся незнакомые слова и имена, аббревиатуры и прочие аномалии. Текст после ручного набора или коррекции. Отличие этого текста от текста после программы OCR состоит в том, что ошибки ручного набора совсем не такие, как ошибки сканирования. При ручном наборе обычно допускают опечатки, когда вместо нужной клавиши нажимают соседнюю и ошибки неграмотности, когда, например, вместо слова «корова» пишут «карова» и т.п. Текст без формул и адресов Интернет. По классификации авторов программы это тоже самое, что и текст после ручного набора, но если пользователь уверен, что в тексте нет формул и Интернет-адресов и выбирает этот режим, программа будет работать быстрее, поскольку анализаторы формул и адресов Интернет отключаются. Тексты в дореволюционной орфографии вам вряд ли встретятся, поэтому мы не будем тратить время на их рассмотрение. HTML документы Текст анализируется и исправляется в соответствии с правилами экранной типографики для HTML-документов. Текст также проверяется на наличие ошибок ручного ввода. Для того, чтобы начать работать с текстом, откройте его в окне программы с помощью команды меню Файл → Открыть, горячих клавиш <Ctrl> + <O> или щелкнув по кнопке Открыть файл. Все как в Word. Программа поддерживает все основные типы текстовых файлов за исключением формата docx Word 2007. Предположим, что файл, который нам необходимо обработать, имеет расширение doc. Для примера возьмем страницу из компьютерного журнала со сложным форматированием (рис. 1). Теперь с помощью программы FineReader выполним ее распознавание, причем, чтобы усложнить задачу, выберем заниженное для распознавание текста разрешение - 200 dpi - и не будем пользоваться средствами исправления ошибок FineReader. Передадим распознанный текст в Word, сохраним его на жестком диске и откроем с помощью программы AfterScan. Сравнивая рисунки 1 и 2 замечаем, что программа уже проделала немалую работу: убрала со страницы иллюстрации, переформатировала текст в одну колонку и изменила стиль заголовка. Для простоты удалим текст врезок, хотя, если его нужно сохранить, все врезки из основного текста переносятся в коне статьи. Теперь можно выполнить OCR-чистку. Нажимаем клавишу <F8>.

Рис. 1 Страница из журнала

Рис. 2 Текст в окне программы AfterScan
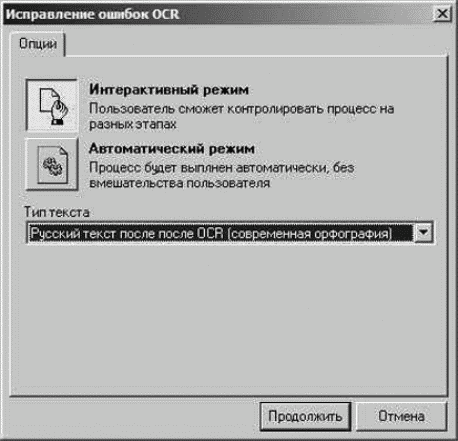
Рис. 3. Исправление ошибок OCR
Откроется окно, показанное на рис. 3. здесь нам предлагается выбрать режим чистки (интерактивный или автоматический) и тип текста. Для того, чтобы понять, как работает программа, выберем интерактивный режим, в котором каждый этап чистки будет выполняться под контролем пользователя. Впоследствии, освоившись с программой, вы можете для экономии времени выбирать автоматический режим. Поскольку в нашем распоряжении версия программы Express, выбирать тип текста мы не можем, по умолчанию выбран Текст в современной орфографии (OCR), который, впрочем, подходит для решения большинства задач. Нажимаем кнопку Продолжить. Откроется окно, показанное на рис. 4, в котором будет видно название выполняемой в данный момент задачи и другая служебная информация. Время выполнения чистки сильно зависит от объема текста и быстродействия вашего компьютера. После окончания чистки откроется следующее окно (рис. 5). Из 616 слов в тексте программа обнаружила 91 слово, которых нет в словаре или которые программа читает ошибочными, причем из этих слов три повторяются неоднократно. В соответствии со своими интеллектуальными алгоритмами программа решила, что эти слова хоть неизвестные, но не ошибочные, и просит пользователя подтвердить это решение. С удовлетворением отмечаем, что программа не ошиблась. А вот если бы она допустила ошибку в каком-нибудь слове, его нужно было бы переместить в раздел Ошибочные слова для последующего исправления. Нажимаем кнопку Продолжить. Откроется окно, показанное на рис. 6. В этом окне программа сообщает статистику проделанной правки текста и предлагает выполнить аналитические замены в словах. Эти замены производятся опять-таки по внутренним интеллектуальным алгоритмам программы. По умолчанию режим аналитических замен включен, но от него можно отказаться. Какие-либо советы по выбору режима здесь давать сложно: попробуйте оба и выберите тот, в котором программа покажет лучшие результаты.

Рис. 4 Окно выполнения задачи

Рис. 5. Первый шаг чистки
Нажмите кнопку Продолжить. Откроется окно, показанное на рис. 7. Это информационное окно, никаких операций с ним выполнять не требуется. Ознакомившись с его содержанием, нажмите кнопку Продолжить. Откроется окно, показанное на рис. 8. Это окно Журнала исправлений. Журнал исправлений содержит список всех измененных и всех не распознанных слов. Если слово было изменено, то в журнале будут показаны исходный и измененный варианты. Если слово было не распознано, то в журнале оно будет показано со снятой галочкой и без замены. В этом случае можно либо установить флажок, подтверждая, что это слово не содержит ошибок, либо ввести правильное слово. Для этого нужно дважды щелкнуть мышью по этому слову. Важную роль играет цвет строк журнала. Исправленные слова выделяются фиолетовым цветом, не распознанные - розовым. Если вы отменяете замену, сделанную программой или наоборот ставите галочку против не распознанного слова без замены, это слово автоматически будет читается правильным (новым) словом и выделяется зеленым цветом. Новые слова автоматически добавляются в буфер словаря. Операции в журнале можно производить с помощью клавиатуры и/или мыши. Преимущество такого редактирования состоит в том, что нет необходимости искать и исправлять ошибки в тексте, поскольку программа автоматически правит текст при работе с журналом. Если же вам все таки нужно внести какие-то коррективы в сам текст, то вы можете это сделать, переключившись в окно редактора нажатием клавиш <Shift> + <Enter>. Чтобы вернуться обратно в журнал нажмите <F10> или используйте мышь. При выборе слова в журнале, автоматически генерируется список возможных вариантов для этого слова. Предложенные слова появляются в контекстном меню и в окне Панель Вариантов. Чтобы выбрать тот или иной вариант с клавиатуры, используйте комбинации клавиш <Ctr> + <1>, <Ctrl> +<2> и т.д. Конечно, все можно оставить «как есть», выполнив окончательную правку текста в Word, но автор не советует этого делать. Почему? Да потому, что программы, основанные на интеллектуальных технологиях, работают тем лучше, чем более тщательно их обучают, формируя пользовательский словарь Сохранение журнала на диск возможно во всех версиях программы, кроме Express. Журнал сохраняется и загружается автоматически вместе с файлом документа. Если файл документа не сохранить, то его журнал тоже будет потерян. При открытии файла происходит процесс сверки журнала с текстом документа и восстановление цветовых пометок. Если файл был отредактирован отдельно и уже не соответствует журналу, то все неправильные и несоответствующие слова будут удалены из журнала. Каждый раз, когда вы делаете какие-то исправления в тексте и возвращаетесь в журнал, происходит синхронизация журнала с текстом. Если в журнале очень много слов, то синхронизация может занимать заметное время. В этом случае просто разбейте текст на несколько частей и обрабатывайте их по очереди. После обработки в окончательном тексте (рис. 9) слова могут быть помечены следующими цветами: Черный - правильное слово русского или английского языка. Оставлено без изменений. Темно-синий - найден единственный правильный вариант исправления. Голубой - найдено более одного варианта исправления. Программа использует наиболее вероятный вариант, остальные варианты тоже сохраняются в журнале и доступны через выпадающий список. Зеленый - неизвестное слово повторяется в тексте несколько раз и удовлетворяет правилам построения слов в языке. Скорее всего новое слово. Зелено-голубой - сокращение, аббревиатура или другие аномалии, которые скорее всего не требуют исправления, но требуют проверки. Красный - слово не исправлено и не распознано. Требуется проверка и исправление пользователем. После окончания правки из окончательного текста нужно убрать цветовые пометки, выполнив команду Процесс → Убрать цветовую пометку. Если файл был сохранен в формате txt, не поддерживающим сохранение цветов текста, то при повторном открытии этого файла, цветовых пометок, естественно, видно не будет. Однако если вместе с файлом открылся журнал исправлений, то восстановить цветовую пометку можно командой Формат → Восстановить цветовую пометку. Другим режимом работы программы является режим Переформатирование (<F7>). Он позволяет удалить из текста: • Переносы с разрывом слов; • Жесткие переносы в конце каждой строки; • Последовательность пробелов для обозначения красной строки. • Выравнивание текста по ширине путем вставления дополнительных пробелов между словами. • Разбиение текста на колонки.

Рис. 6. Шаг 2 чистки

Рис. 7. Шаг 3 чистки

Рис. 8 Нераспознанные слова

Рис. 9 Итоговый текст с цветовыми пометками
Эти проблемы обычно бывают в текстах, созданных в старых или несовершенных текстовых процессорах. Загрузите в программу AfterScan текст, предназначенный для правки, и нажмите клавишу <F7>. Откроется окно, показанное на рис. 10.

Рис. 10 Окно Переформатирование
Выберите нужные вам опии и нажмите ОК. Имейте в виду, что если выбрать опию Убирать жесткие переносы строки, отредактированный текст может потерять разбиение на абзацы. Поэкспериментируйте с опцией Разрывы абзацев и, возможно, вы добьетесь желаемого результата. Вообще, нужно понимать, что как и любая компьютерная программа, AfterScan облегчает вам редактирование текста, но не способна полностью заменить человека, а иногда может внести и свои собственные ошибки в редактируемый текст. И последний совет. Работая с программой AfterScan, сохраняйте промежуточные результаты в отдельные файлы. Во-первых, потому, что результаты обработки вас могут не удовлетворить и вы захотите вернуться к исходному варианту, а, во-вторых, программа может не полностью поддерживать особенности форматирования текста в самых последних версиях Word. В этом случае, закончив править текст в AfterScan, сохраните его на диске, потом откройте той версией Word, в которой вы работаете, и окончательно сохраните текст уже в формате этой версии текстового процессора.
Последние комментарии
1 час 6 минут назад
2 часов 12 минут назад
3 часов 21 минут назад
15 часов 19 минут назад
15 часов 33 минут назад
18 часов 59 минут назад